Release Notes for v0.8.0
2020-02-06First release of rs-pbrt in 2020!
The command line interface changed slighlty, so we do not have to
specify -i anymore. The old help information looked like this:
# old
> ./target/release/rs_pbrt -h
Usage: ./target/release/rs_pbrt [options]
Options:
-h, --help print this help menu
-i FILE parse an input file
-t, --nthreads NUM use specified number of threads for rendering
-v, --version print version number
The new command line interface drops the -i to make it more
consistent with other executables (and the original C++ code):
# new
> ./target/release/rs_pbrt -h
pbrt 0.8.0
Parse a PBRT scene file (extension .pbrt) and render it
USAGE:
rs_pbrt [OPTIONS] <path>
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
OPTIONS:
-t, --nthreads <nthreads> use specified number of threads for rendering [default: 0]
ARGS:
<path> The path to the file to read
Many files changed:
97 files changed, 59990 insertions(+), 12541 deletions(-)
...
new file src/samplers/maxmin.rs
...
new file src/samplers/stratified.rs
A lot of files changed just because I decided to run:
cargo clippy
Clippy
According to its Github repository, Clippy is:
A collection of lints to catch common mistakes and improve your
Rust code.
I did mention some clippy keywords in the commit comments, so you can use those here to find more information about each lint.
Issues
Beside those changes there were two new files added to implement two new samplers:
- The implementation of
MaxMinDistSamplerwas documented in issue #121. - The implementation of
StratifiedSamplerwas documented in issue #122. - I closed issue #125 for now without really addressing or solving it, so it might be re-opened in the future, when we stumble across a scene with hundreds of light sources.
Performance
I started looking at the performance of my Rust based
implementation against the original C++ code and made some
progress, but I think the series of v0.8.x releases to follow should
address this until rs-pbrt kind of matches the speed of the C++
counterpart. So far the highest priority was to be feature
complete and a nearly perfect match of the resulting (rendered)
images (pixel by pixel).
So, those two topics are still important and actually I would like to get some help from the community to make sure that we match the C++ counterpart as closely as we can. Here are some links to example scenes:
- The official resources for
PBRT contain some interesting
scenes for
pbrt-v3(the C++ counterpart). - Some of those scenes can also be found in my own GitLab
repository
where I collect additional scenes in both
.pbrtas well as in.blend(there is an executable calledparse_blend_filewhich can render those Blender binary files) and/or.assfile format (seeparse_ass_fileexecutable and Arnold's native scene description file format). - Benedikt Bitterli’s rendering resources
webpage provides some
scenes for three different renderers. Beside
pbrt-v3scenes he provides the same scenes for Mitsuba (there is aMitsuba 2on the horizon), and his own Tungsten renderer. - I'm sure there are other resources and I'm happy to learn about
them. Please drop me an email (rs-pbrt [at] posteo [.] de) if
you find some. I also would like to hear about problems you might
run into using
rs-pbrton some of the.pbrtfiles you come along. Either report by email or open a issue about it.
But let's get back to the performance improvements I archieved so
far. Let's measure the rendering times (on two different machines)
for the Cornell Box for various rs-pbrt commits/releases against
the C++ counterpart.
C++
# make sure we render the same scene
# (copy which is not version controlled)
cp assets/scenes/cornell_box.pbrt assets/scenes/performance.pbrt
# 4 cores laptop
$ time ~/builds/pbrt/release/pbrt assets/scenes/performance.pbrt
pbrt version 3 (built Apr 1 2019 at 17:45:44) [Detected 4 cores]
...
real 0m4.066s
user 0m15.294s
sys 0m0.044s
# 8 cores desktop
> time ~/builds/pbrt/release/pbrt assets/scenes/performance.pbrt
21.340u 0.094s 0:03.10 691.2% 0+0k 0+8576io 0pf+0w
So the C++ code renders the test scene on the laptop (4 cores) in more than 15 seconds and on the desktop machine (8 cores) in just a bit more than 3 seconds.
Rust
Commit 3e7c100
Lets start with an older version of rs-pbrt. This was before I
started replacing dynamic dispatch (traits) by enums. At that time
there were 26 traits.
# 4 cores laptop
$ git checkout 3e7c100
$ make
$ time ./target/release/rs_pbrt -i assets/scenes/performance.pbrt
pbrt version 0.7.1 [Detected 4 cores]
...
real 0m9.684s
user 0m35.493s
sys 0m1.223s
# 8 cores desktop
> time ./target/release/rs_pbrt -i assets/scenes/performance.pbrt
pbrt version 0.7.1 [Detected 4 cores]
...
52.560u 1.457s 0:07.18 752.2% 0+0k 0+1016io 0pf+0w
So, that's more than 35 seconds on the laptop (4 cores) and about 7 seconds on the desktop machine (8 cores).
Commit d70666c
# 4 cores laptop
$ git checkout d70666c
$ make
$ time ./target/release/rs_pbrt -i assets/scenes/performance.pbrt
pbrt version 0.7.3 [Detected 4 cores]
...
real 0m8.381s
user 0m30.831s
sys 0m1.332s
# 8 cores desktop
> time ./target/release/rs_pbrt -i assets/scenes/performance.pbrt
pbrt version 0.7.3 [Detected 8 cores]
...
45.131u 1.533s 0:06.22 750.1% 0+0k 0+1016io 0pf+0w
That is already 5 seconds faster (30 seconds) on the laptop (4
cores) and about 6 seconds (in total) on the desktop machine (8
cores). But it's hard to tell if replacing most of the traits by enums
really made a difference so far. Most likely the change of
vec3_permute<T>(...) and pnt3_permute<T>(...) (as described
here) made a
difference.
Commit 66a0ff5
# 4 cores laptop
$ git checkout 66a0ff5
$ make
# (no '-i' anymore)
$ time ./target/release/rs_pbrt assets/scenes/performance.pbrt
pbrt version 0.7.3 [Detected 4 cores]
...
real 0m7.030s
user 0m25.073s
sys 0m1.403s
# 8 cores desktop (no '-i' anymore)
> time ./target/release/rs_pbrt assets/scenes/performance.pbrt
pbrt version 0.7.3 [Detected 8 cores]
...
36.445u 1.515s 0:05.11 742.6% 0+0k 0+1016io 0pf+0w
That is another 5 seconds faster (25 seconds) on the laptop (4 cores) and about 5 seconds (in total) on the desktop machine (8 cores).
v0.8.0 release (commit fba9d76)
# 4 cores laptop
$ git checkout master
$ make
# (no '-i' anymore)
$ time ./target/release/rs_pbrt assets/scenes/performance.pbrt
pbrt version 0.8.0 [Detected 4 cores]
...
real 0m5.763s
user 0m20.591s
sys 0m1.509s
# 8 cores desktop (no '-i' anymore)
> time ./target/release/rs_pbrt assets/scenes/performance.pbrt
pbrt version 0.8.0 [Detected 8 cores]
...
31.195u 1.587s 0:04.48 731.4% 0+0k 0+1016io 0pf+0w
That is another 5 seconds faster (20 seconds) on the laptop (4 cores) and less than 5 seconds (in total) on the desktop machine (8 cores).
I'm not going into further details. You can check the commit messages
and look at the changes in the source code yourself, if you are
interested, but perf and heaptrack are my weapons of choice to
investigate where time might be wasted, but even the graphs for memory
allocations help:
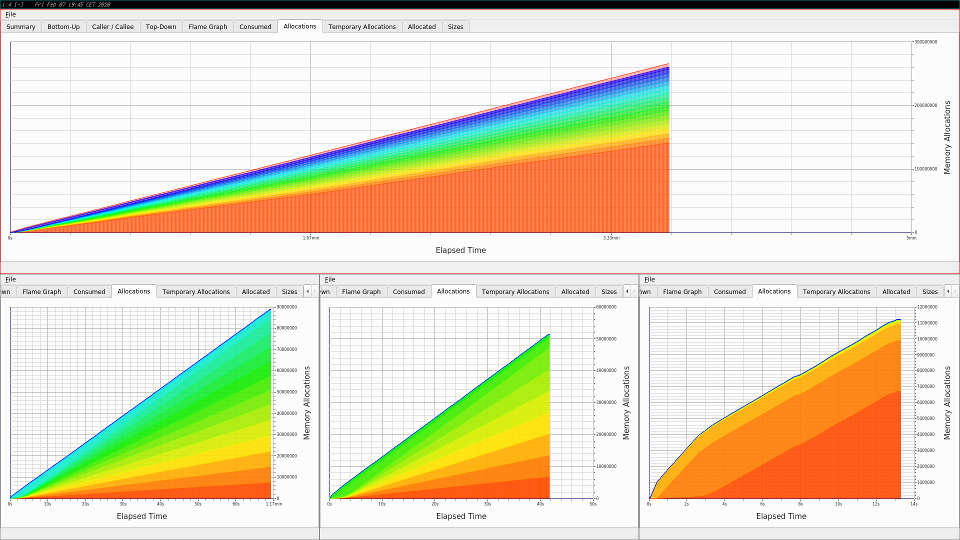
Lets talk a bit about the last improvement which probably made
rs-pbrt render on the laptop 5 seconds faster. On the C++ side a
very important bit of information during rendering is created and kept
in the class SurfaceInteraction:
class SurfaceInteraction : public Interaction {
...
public:
...
mutable Vector3f dpdx, dpdy;
mutable Float dudx = 0, dvdx = 0, dudy = 0, dvdy = 0;
...
};
While learning Rust and at the same time digging deeper into the C++
code of the renderer I wasn't sure if several threads will ever use an
instance of the class SurfaceInteraction. If you look up the
mutable specifier of
C++ you find:
mutable - permits modification of the class member declared mutable
even if the containing object is declared const.
On the Rust side I stumbled upon Interior Mutability and while reading about std::cell I found:
Shareable mutable containers exist to permit mutability in a
controlled manner, even in the presence of aliasing. Both Cell<T> and
RefCell<T> allow doing this in a single-threaded way.
However, neither Cell<T> nor RefCell<T> are thread safe (they do not
implement Sync). If you need to do aliasing and mutation between
multiple threads it is possible to use Mutex, RwLock or atomic types.
Just to be on the safe side I used
RwLock within
a SurfaceInteraction, but, after looking deeper into how long a
SurfaceInteraction is used, I thought, lets try to get away with a
Cell, which
might be less expensive to use.
@@ -271,31 +268,31 @@ pub struct SurfaceInteraction<'a> {
pub dpdv: Vector3f,
pub dndu: Normal3f,
pub dndv: Normal3f,
- pub dpdx: RwLock<Vector3f>,
- pub dpdy: RwLock<Vector3f>,
- pub dudx: RwLock<Float>,
- pub dvdx: RwLock<Float>,
- pub dudy: RwLock<Float>,
- pub dvdy: RwLock<Float>,
+ pub dpdx: Cell<Vector3f>,
+ pub dpdy: Cell<Vector3f>,
+ pub dudx: Cell<Float>,
+ pub dvdx: Cell<Float>,
+ pub dudy: Cell<Float>,
+ pub dvdy: Cell<Float>,
Of course that triggered other lines of code to change, but I think
this made the difference for the last 5 seconds. So, let's make the
series of v0.8.x releases about further performance improvements
until we match the C++ code speedwise (or make the Rust version even
faster).
The End
I hope I didn't forget anything important. Have fun and enjoy the v0.8.0 release.